I’ve debugged the same conversion bug in five different components. Each one fixed independently. Each one free to drift apart again.
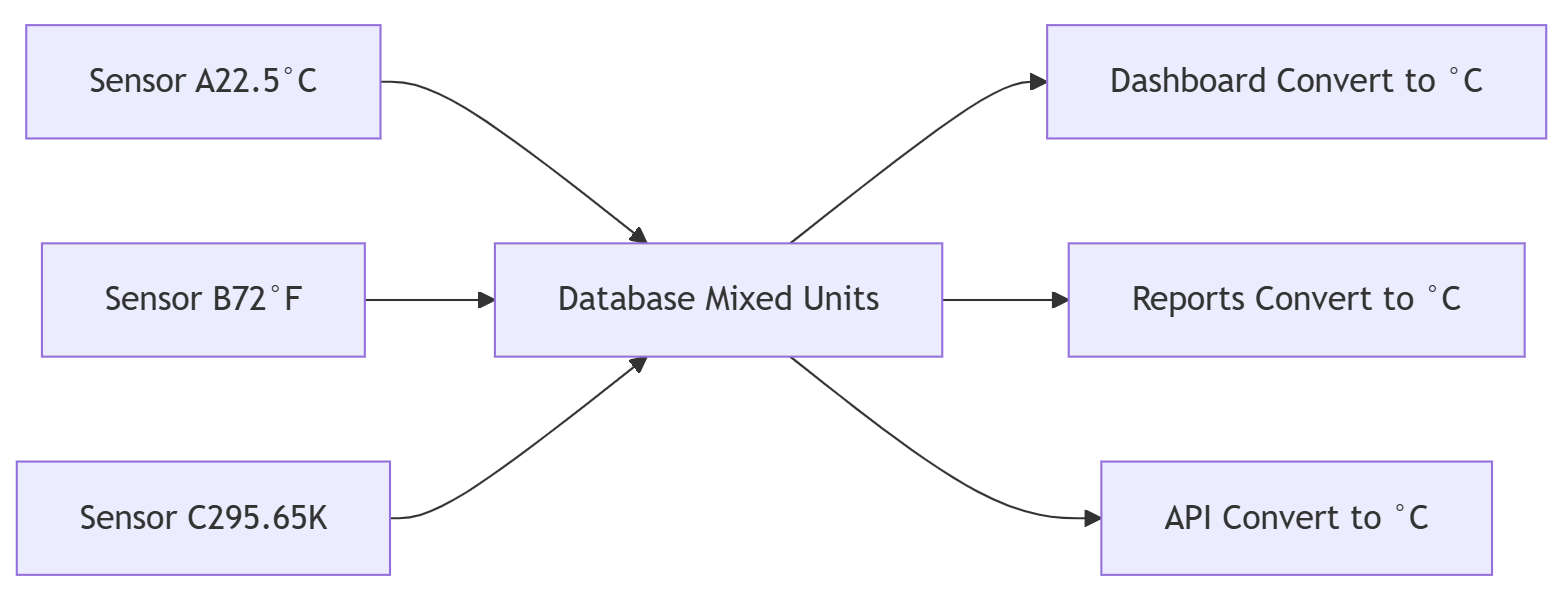
The system aggregates sensor data from multiple IoT vendors. Each sends temperature in a different unit:
Mixed units stored as-is
┌────────┬───────────┬───────┬────────────┐
│ id │ sensor_id │ value │ unit │
├────────┼───────────┼───────┼────────────┤
│ 1 │ A-101 │ 22.5 │ celsius │
│ 2 │ B-202 │ 72 │ fahrenheit │
│ 3 │ C-303 │ 295.65│ kelvin │
└────────┴───────────┴───────┴────────────┘Every component that reads this data carries its own conversion logic. Dashboards convert. Reports convert. SQL aggregations convert — CASE statements before every AVG. When a rounding error surfaces, you find it in one place and miss it in four others.
The fix isn’t in the reads. It’s in the writes.
Transform incoming readings to a standard unit at the ingestion boundary. Before anything touches the database, convert to Celsius:
Standardized to Celsius
┌────────┬───────────┬───────┬─────────┐
│ id │ sensor_id │ value │ unit │
├────────┼───────────┼───────┼─────────┤
│ 1 │ A-101 │ 22.5 │ celsius │
│ 2 │ B-202 │ 22.2 │ celsius │
│ 3 │ C-303 │ 22.5 │ celsius │
└────────┴───────────┴───────┴─────────┘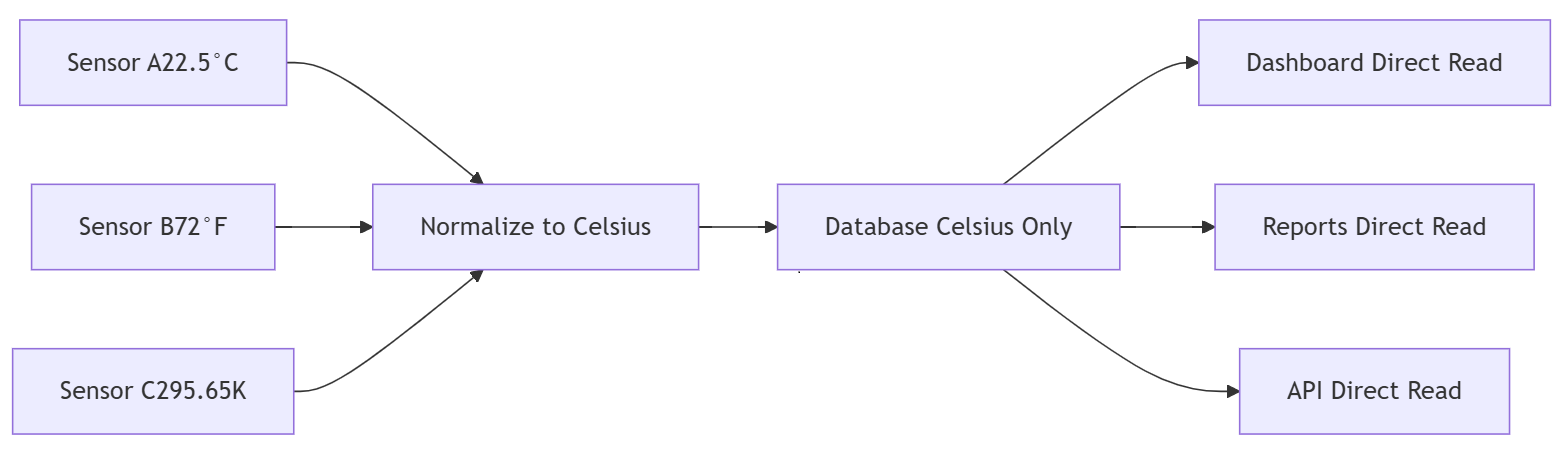
Queries work without conversion logic. AVG(value) calculates correctly. The conversion logic lives in one layer — testable, deployable, fixable once.
This isn’t specific to IoT. ETL pipelines, API aggregation layers, any integration point pulling from multiple sources - it’s the same pattern. Standardize at the boundary. The database stores one format. Reads don’t need to know how the data arrived.
The conversion bug you keep finding in new places isn’t a bug. It’s a write-time decision you didn’t make.